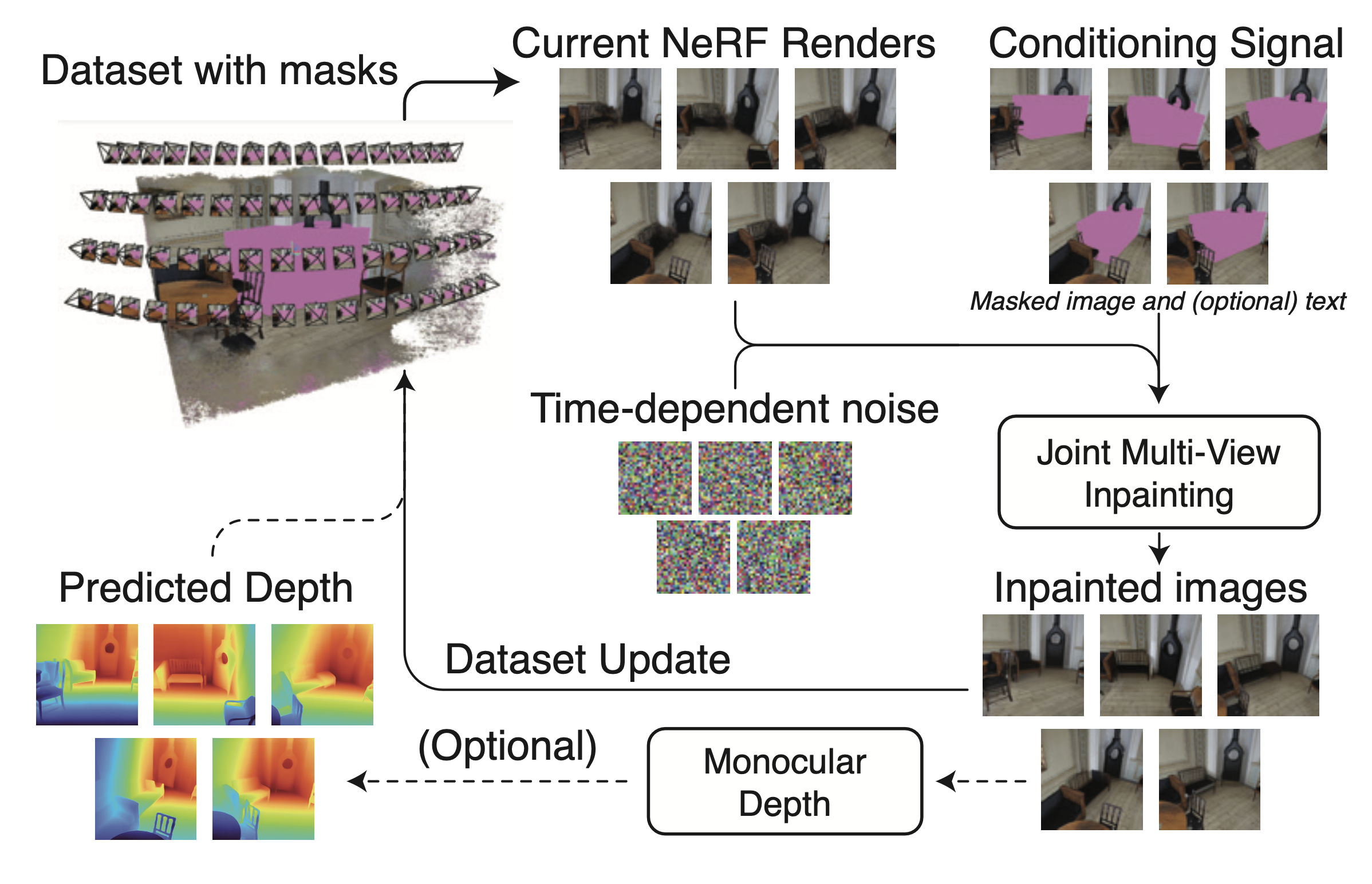
Method
We find that tiling images in a 2x2 grid produces more 3D consistent inpaints. We extend this "Grid Prior" property to more than 4 images by averaging diffusion model predictions, and we show how to use it iteratively in the NeRF framework with dataset updates. Please see the paper for more details.